Applying All Recent Innovations To Train a Code Model
ML is changing fast!
Recently Meta has released LLaMA model that surprised many people - it packed a lot of magic in a small size. The 12b version was comparable with OpenAI’s GPT-3 largest 175B model in quality.
MosaicML released the MPT-7B model, which has a context of 60k tokens, thanks to the ALiBi position encoding.
BigCode released the StarCoder model that hits 30.4% on HumanEval pass@1, and they also released a code dataset cleaned of personally identifiable information, called The Stack.
Replit recently released the replit-code-v1-3b model trained on code that follows some LLaMA innovations and it shows great metrics, but it has no fill-in-the-middle capability, no diffs, and it has seen no data other than code.
We plan to make the model publicly available.

LLaMA Innovations
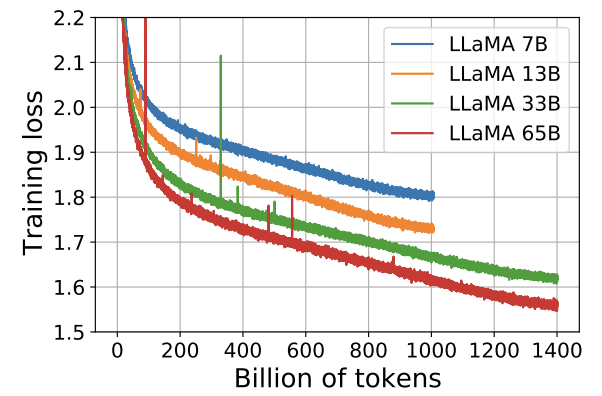
The number one thing about LLaMA is that it was trained for 1T tokens (and larger models for 1.4T tokens). But that alone is not enough, the transformer architecture and hyperparameters must be right to continue training for that long.
Architecture: LLaMA doesn’t have the bias terms in self-attention and in MLP - that probably allows weight decay to work better. Self-attention runs independently from MLP, not sequentially - this makes calculations a bit faster because they don’t have to wait for each other. LLaMA also uses RMSNorm instead of LayerNorm, but that shouldn’t be important.
Hyperparameters: the most interesting is the batch size of 4M tokens. Early in training, many tokens are surprising for the model, and it gets interesting updates. But to run for longer, each batch needs to have diverse data that is not yet predictable, that’s why it should be so big.
Figure 1: LLaMA loss and metrics get monotonically better for 1T tokens and beyond.
ALiBi Position Encoding
Transformers traditionally had absolute position encoding, which means each position in the context of 2048 or so tokens has its own trainable vector. It’s horrible, of course, because the same tokens moved left or right will produce different activations! But some still use it, notably the StarCoder model.
There are three widely used solutions to this:
- Relative Attention, introduced in the Transformer XL paper (with a not-very-clear explanation)
- Rotary Embeddings (LLaMA uses this one)
- ALiBi
Relative Attention has a big disadvantage: it adds trainable parameters. That means the initialization must be right, gradients must be right. We tried wavelets some time ago instead of trainable parameters and it worked just as well, proving there’s no need for trainable parameters here, really.
Both Rotary Embeddings and ALiBi are great, but ALiBi has an additional advantage - extendable context size, compared to what was used in pretrain. Not immediately in our experience, but after a bit of fine-tuning - still a big advantage.
But let’s directly compare the latter two on a short 15e9 token run:
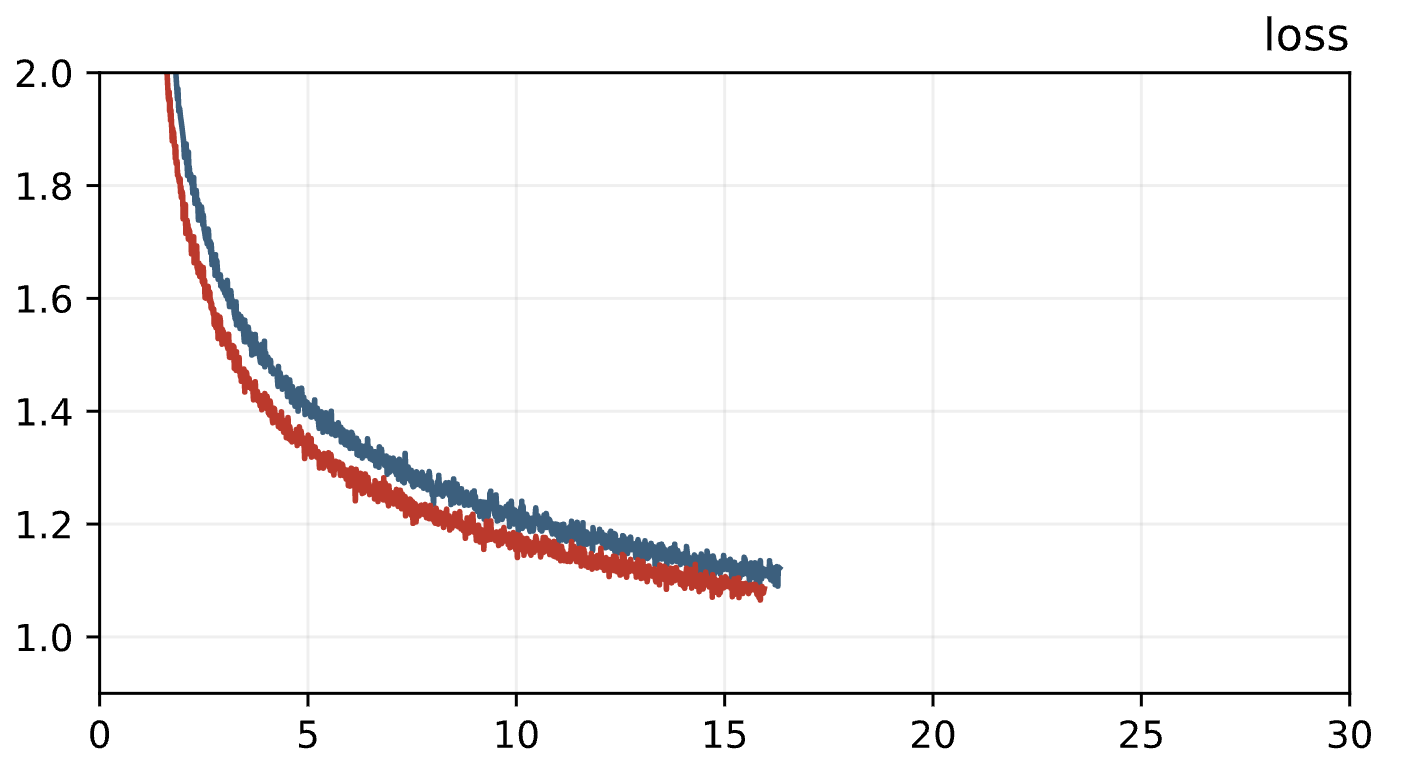
 ALiBi
ALiBi Rotary
RotarySo ALiBi even works better for our setup!
Early Dropout
Researchers at Meta proposed using dropout in early training to improve underfitting (not overfitting). The way it works is this: put dropout layers at many places in the transformer, gradually turn down the drop rate from 10..15% to zero at the first 20% of the training run.
According to the paper, it can give a couple of percent on metrics for free, on the test set. Trying this using the same short training run we’ve got:
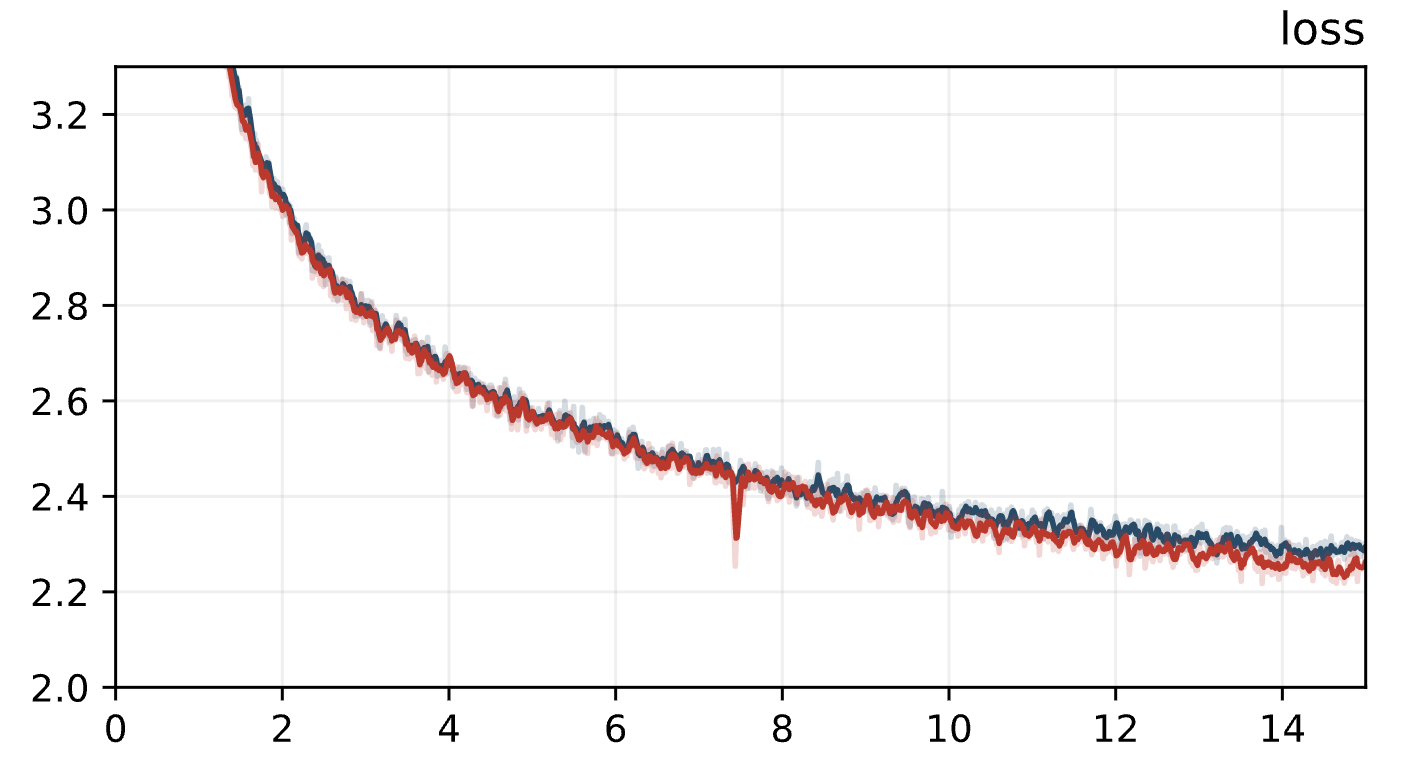
The red run with early dropout has a clear advantage on the training loss (never mind the little drop).
Multi-Query Attention
One of the ways to have a large context size with small memory usage is Multi-Query Attention, used at scale in PaLM models. A short explanation is this: in Multi-Head Attention a self-attention layer produces K, V and Q (keys, values and queries) for each head. But in Multi-Query Attention keys and values are produced just once (not for each head), only the queries are different for each attention head. Look at 2204.02311 for a detailed explanation.
This allows for a smaller KV cache while sampling and improved inference speed.
It was recently used in the StarCoder models, where it helps to handle a big context size of 8192.
LiON
Another recent development is LiON, an optimizer that makes a bold claim - that it can replace Adam. Adam ruled the world of deep models since its introduction in 2014, nearly a decade!
Various people are trying LiON on their projects, with varying degrees of success. A good starting point to look around is the lion-pytorch on github from Phil Wang aka lucidrains (thank you man!).
The main problem is the hyperparameters, which are well established for Adam, but it’s still a bit of guesswork for LiON. There are three: betas, weight decay, learning rate. We took β1=0.95, β2=0.98 without checking, and tested LR and WD:
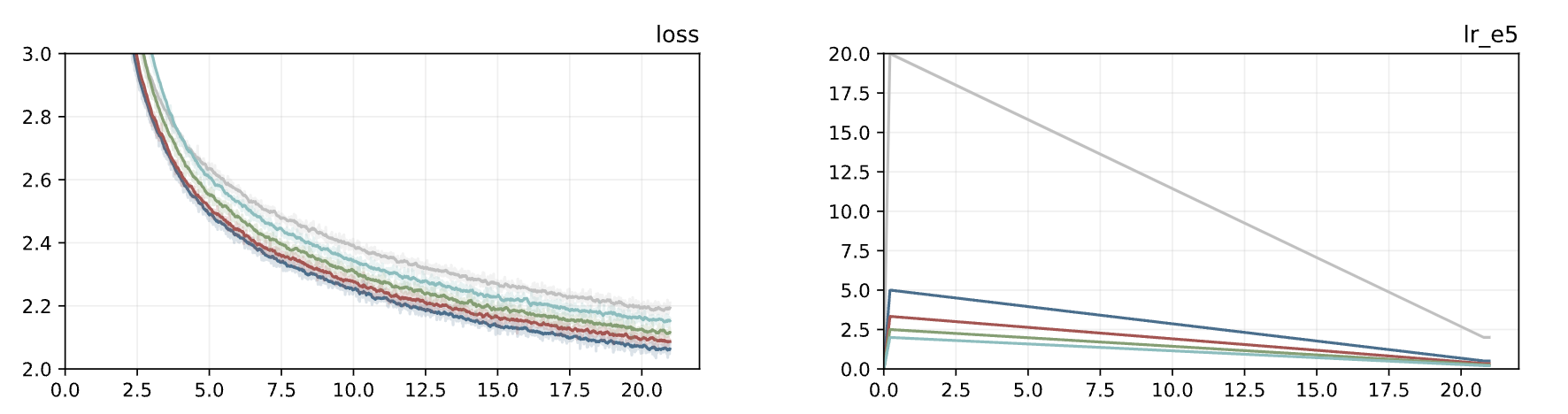
LR: gray is Adam with lr=20e-5, others are LiONs from 2e-5 to 5e-5 (the best).
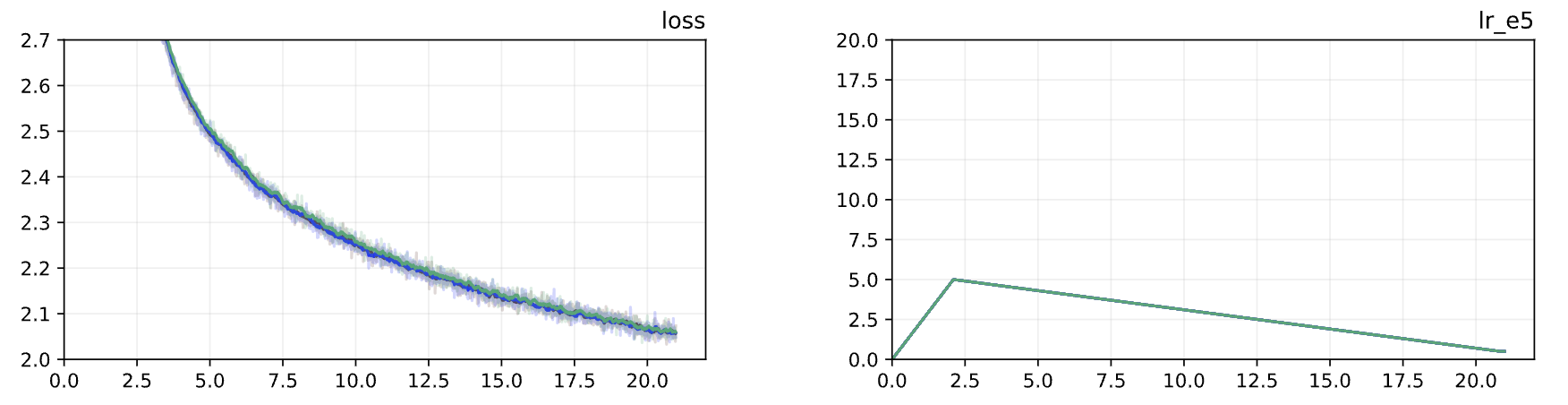
WD: a higher weight decay (green wd=0.8) is slightly worse in the middle (within error bars?) for this short run but it’s just as good at the end, compared to wd=0.6 and wd=0.4.
We took lr=5e-5 (four times lower than the Adam learning rate) and wd=0.8 (eight times higher than in Adam).
By the way, the low effect of weight decay on the final result is consistent with the LiON paper: they changed WD from 0.5 to 2.0 to a very little effect on final performance, especially with a higher learning rate.
The Data
We use Red Pajama as a text dataset, Stack Dedup 1.2 for plain code, and our own internal dataset for diffs.
We use fill-in-the-middle training almost exactly as in 2207.14255 (but we limit the “middle” part size to 4k chars)
Hyperparameters
| Optimizer | LiON β1=0.95, β2=0.98 | Batch size | 2M tokens |
| LR | 5e-5 | Context size | 4096 |
| LR schedule | linear to zero with warmup | Dropout | p=0.1 |
| Weight Decay | 0.8 | Dropout schedule | to zero at 20% of training |
Conclusion
The model is called “202305-refact2b-mqa-lion”, it has 1.6b parameters, we will release the weights for everyone to check out!
Get more information
Thank you!