Refact.ai Agent + Claude 3.7 Sonnet tops Aider's polyglot benchmark with a 76.4% score [Updated: Now 92.9%]
UPD: Refact.ai AI Agent powered by Claude 3.7 Sonnet, has now achieved top performance on the Aider Polyglot Benchmark:
- 93.3% with Thinking
- 92.9% without Thinking
Read more about the new score and Refact.ai Agent’s approach to autonomous programming in this blog post. The text below details our original score, benchmarks vision, and the improvements that led to these results.
Refact.ai Agent, powered by Claude 3.7 Sonnet, has achieved an impressive 76.4% score on Aider’s polyglot benchmark — without thinking capabilities enabled.
This puts Refact.ai Agent at the top of the LLM leaderboard, surpassing Aider’s own score of 60.4% with the same model, as well as with DeepSeek Chat V3, GPT-4.5 Preview, ChatGPT-4o, and others.
This high score was made possible by our iterative approach to solving programming tasks. In your IDE, Refact.ai doesn’t just generate code — it ensures it works by iterating until it achieves a successful result. This guarantees highly accurate, production-ready outcomes with minimal human intervention.
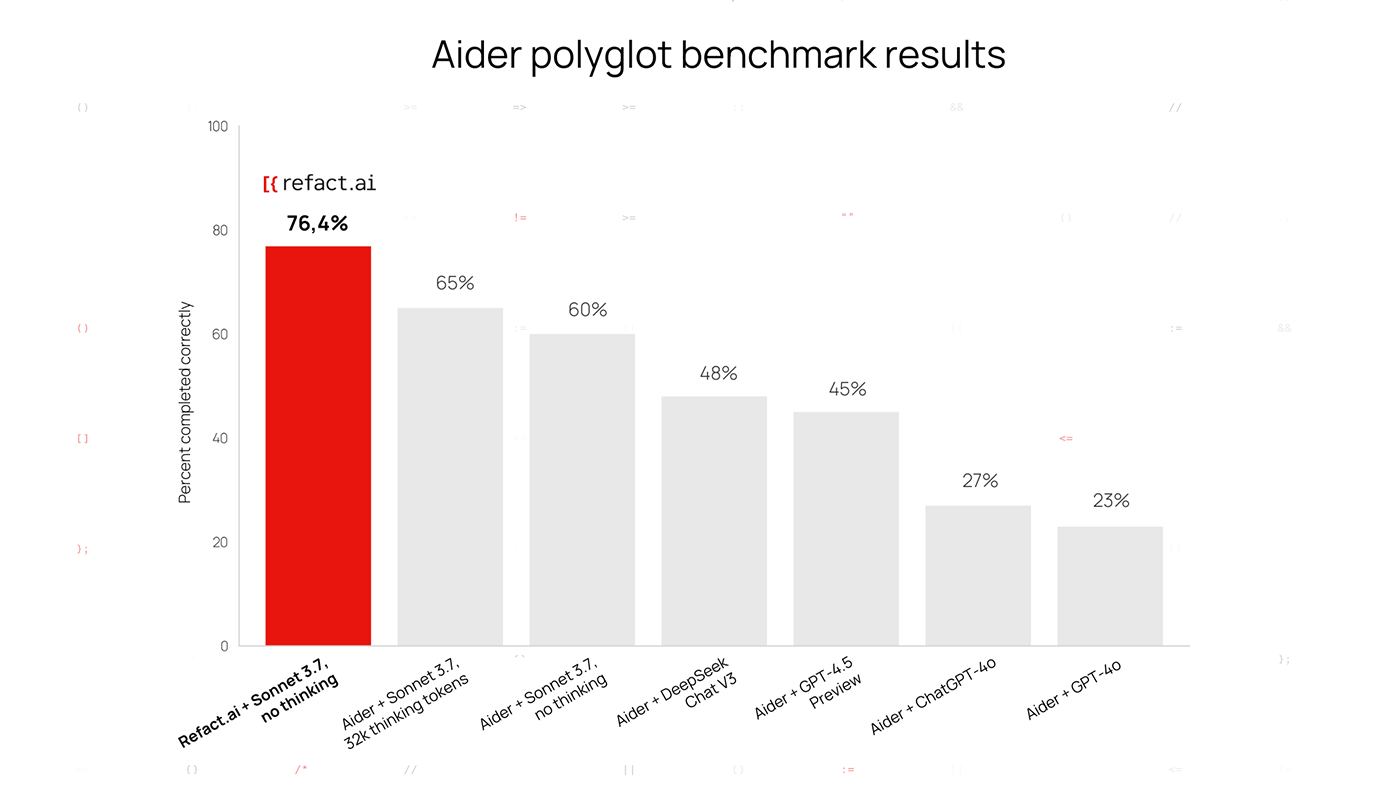 Refact.ai Agent + Claude 3.7 Sonnet achieved a 76.4% score on Aider’s polyglot benchmark [UPDATED: Now scoring 92.9%].
Refact.ai Agent + Claude 3.7 Sonnet achieved a 76.4% score on Aider’s polyglot benchmark [UPDATED: Now scoring 92.9%].About Aider’s polyglot benchmark
Aider polyglot benchmark evaluates how well AI can handle 225 of the hardest coding exercises from Exercism across C++, Go, Java, JavaScript, Python, and Rust.
It focuses exclusively on the most challenging problems and measures:
- Can AI write new code that integrates seamlessly into existing codebases?
- Can AI successfully apply all its changes to source files without human intervention?
This makes Polyglot one of the most representative benchmarks for testing autonomous AI in programming — not just for raw code generation but also for reasoning, precision, and execution.
Explore the full test set in the Aider polyglot benchmark repo on GitHub.
Our approach: How Refact.ai achieved highest scores in the polyglot leaderboard
Refact.ai Agent takes a fully autonomous, iterative approach. It plans, executes, tests, self-corrects, and repeats steps as needed to fully complete tasks with high accuracy — without human input.
Other approaches may follow a more manual workflow, relying on pre-defined scripts and requiring ongoing user intervention to provide context, run tests, and guide the AI. The model itself doesn’t form strategies, search files, or decide when to test.
Refact.ai has a different, autonomy-first AI workflow:
- Prompt + tool-specific prompts → User provides task description → AI Agent autonomously solves it within 15 steps (i.e. searches for the relevant data, calls tools, decides when corrections are needed, runs tests, etc.) → Result.
So, Refact.ai interacts with the development environment, verifies its own work, and optimizes resources to solve the task end-to-end, delivering efficient and practical programming flow with a full-scope autonomy. This enables true vibe coding — developers can delegate entire tasks while focusing on other work, then simply receive the final result.
Our approach may slightly differ from what Aider used for solving this benchmark, as our AI agent strategy and vision focus on:
- Full autonomy of AI agent at every step, with no need for human input
- Deep integration with tools and dev environment, enabling Agent to act independently
- Self-testing autonomously when needed, revising earlier steps, testing mid-process, and running multiple checks for accuracy
- Task completion within 15 steps.
____
Update (April 1, 2025): Building on the approach mentioned above, we implemented several improvements to Refact.ai Agent that also increased its score on Aider’s Polyglot Benchmark:
- Doubled limit for AI to solve the task from 15 → 30 — addressing cases where it lacked sufficient steps to finish the solution
- Enforced test execution — to ensure AI validates itself at least once per task.
These enhancements made Refact.ai Agent more reliable for all users — solving tasks more effectively while maintaining optimized token usage. As a result, the benchmark score with Claude 3.7 Sonnet (No-Thinking) increased from 76.4% to 92.9%.
Read the detailed reveal of our approach in this blog post: Refact.ai’s AI Agent achieves the highest score on Aider’s polyglot benchmark: 93.3% with Thinking, 92.9% without
Why we chose Polyglot over SWE Bench
TL;DR: We at Refact.ai see Polyglot a far better measure of AI agents’ problem-solving abilities and their usefulness across a diverse pool of tasks than SWE Bench.
SWE Bench is popular and often seen as a key benchmark for AI coding agents. However, it has significant limitations:
- Only tests Python
- Relies on just 12 repositories (e.g., Django, SymPy)
- Benchmarked models are often pre-trained on these repos (skewing results)
- Only one file is changed per task (unrealistic for typical development work)
- Human-AI interaction is oversimplified (in reality, devs adjust how they collaborate with AI).
In contrast, Polyglot is far more representative and realistic—it measures how well AI can autonomously interact with diverse, multi-language projects, making it much closer to the environments developers work in every day.
So, we’d like to thank Aider for introducing this comprehensive benchmark! It provides great insights into AI coding tools and helps drive better solutions.
Key features of Refact.ai’s autonomous AI Agent
Refact.ai’s advanced AI Agent thinks and acts like a developer, handling software engineering tasks end-to-end.
- Autonomous task execution: Breaks tasks into steps, plans solutions, executes, and deploys code — all with minimal human input.
- Deep contextual understanding: Analyzes your entire environment, generating highly accurate and relevant code.
- Tool integration: Connects with essential dev tools like GitHub, Docker, PostgreSQL, MCP Servers, autonomously interacting with them for completing tasks.
- Memory and continuous improvement: Learns from every interaction, becoming better over time.
- Human-AI collaboration: When faced with obstacles, the Agent can self-correct, and if it requires human input, it natively hands control back to the user, fostering an efficient workflow.
- Open source: Fully transparent and verifiable for trust.
Why this matters for developers
This isn’t just about ranking highly on a benchmark — it’s about real-world coding impact. Refact.ai’s AI agent helps developers and software companies:
- Automate repetitive tasks across the SDLC.
- Focus on core work while the AI handles the rest.
- Deliver faster with the AI Agent working alongside you in your IDE.
- Delegate with confidence, knowing the AI writes reliable, tested code
Get Refact.ai for your IDE
Vibe coding is the future of software development: get 10x productivity with Refact.ai Agent by your side in IDE. Work smarter, not harder — whether you’re debugging, testing, or deploying.
Refact.ai autonomously handles your programming tasks end-to-end like a senior dev: makes multi-file edits, writes accurate code that matches your workflow, and integrates seamlessly with your tools.
Our autonomous AI Agent is available to everyone — get started with Refact.ai today: download it for VS Code or JetBrains.
Want to get it for your team? Please fill out the form to book a demo call.