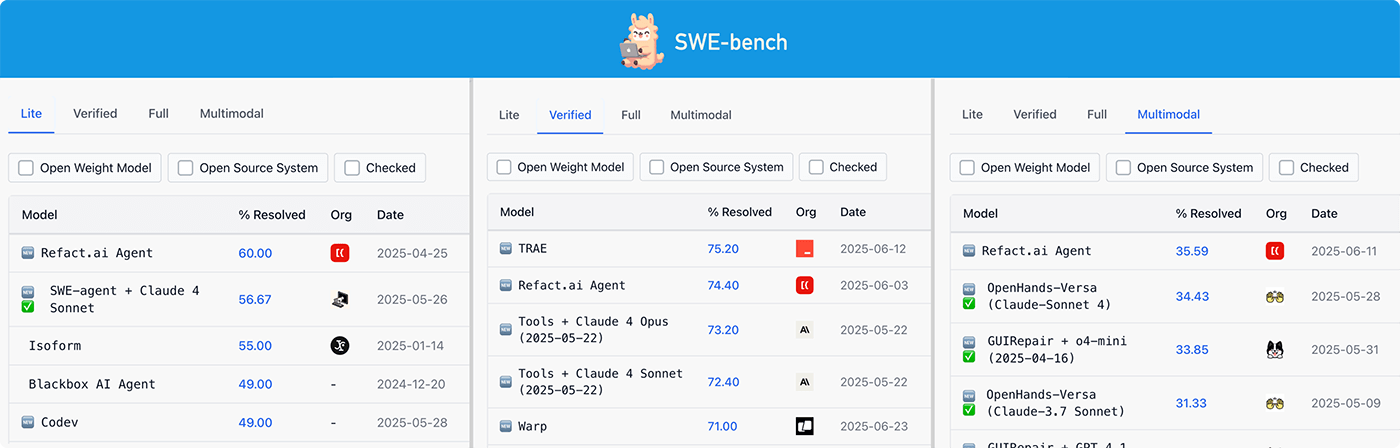
Refact.ai Agent achieved leading results on SWE-bench Multimodal and Verified
Refact.ai Agent has achieved new SOTA results on SWE-bench — the key benchmark for evaluating autonomous AI Agents on real-world coding tasks:
- #1 on SWE-bench Multimodal: 35.59% tasks resolved
- #2 on SWE-bench Verified under pass@1: 74.40% tasks resolved.
With these milestones, it now holds top positions across the SWE-bench tracks — Verified, Light, and Multimodal — proving Refact.ai Agent the best choice for AI programming in different languages.
Notably, we ran every benchmark under pass@1: Refact.ai only had one attempt to solve each task correctly. This setting better reflects how reliable an AI agent is in everyday use, as developers shouldn’t have to spend extra time double-checking its work or babysitting fixes.
The full SWE-bench pipeline we used is open-source and fully reproducible. Our mission is to empower developers with an autonomous AI that amplifies their capabilities. We believe the future of programming is open-source — transparent, customizable, and community-driven — with AI tools built by developers, for developers.
These aren’t just numbers — they’re proof that Refact.ai Agent is a reliable autonomous programming partner. You can run it in VS Code, JetBrains, or self-host: it fixes tough bugs, solves routine tasks you delegate, builds working solutions from scratch, and helps you do more with less manual coding.
#1 AI Agent in SWE-bench Multimodal is Refact.ai
Refact.ai Agent reached the 1st place on SWE-bench Multimodal leaderboard, solving 184 out of 517 tasks (35.59%) with Claude 4 Sonnet.
This benchmark tests whether an AI Agent can handle GitHub issues that include both text and visuals, such as:
- Screenshots of bugs or interface issues
- Design mockups or wireframes
- Diagrams explaining desired functionality
- Error messages with visual context.
Unlike SWE-bench Verified (Python-only), the Multimodal version focuses on web libraries and frontend tasks. That makes SWE-bench Multimodal more representative of real-world debugging, especially in JavaScript environments where bugs are often reported using screenshots.
We ran this benchmark fully autonomously using a locally modified version of the official sb-cli to enforce single-threaded execution. We didn’t use extra agentic tools like debug_script or strategic_planning, which were part of our earlier Verified runs.
Evaluation results:
| Total | Solved | Solved (%) | Not solved | Failed runs |
|---|---|---|---|---|
| 517 | 184 | 35.59% | 326 | 3 |
Achieving #1 on SWE-bench Multimodal makes Refact.ai a top-tier AI Agent for JavaScript tasks. Combined with our leading results on Python-based SWE-bench, it confirms the Agent’s ability to deliver high-quality results across programming languages.
Refact.ai’s open-source approach to SWE-bench
The new run introduced a key upgrade: Anthropic’s Claude 4 Sonnet as the core model, bringing a notable boost in reasoning and code generation. With it, Refact.ai Agent reached a 74.40% score — surpassing our previous best SWE-bench Verified score of 70.4% with Claude 3.7 Sonnet.
Beyond that, this milestone builds on everything we’ve learned from earlier SWE-bench runs. Refact.ai is evolving continuously, and the improvements added along the way helped make this result possible.
Our approach remains focused on reliability and step-by-step problem solving. Key elements of the SWE-bench Verified setup included:
- Open-source Agent prompt, available on GitHub.
- Claude 4 Sonnet as a core model
- A
debug_script()sub-agent that fixes bugs and can modify/create new scripts. - Extensive guardrails to catch when the model is stuck or going off track, and to redirect it back on course.
- Incremental improvements built on our previous Claude 3.7 run.
How does Refact.ai Agent solve the SWE-bench Verified tasks? It follows a four-step strategy defined in its system prompt. The Agent starts by exploring the problem: using tools like cat() to open files, search_symbol_definition(), search_pattern(), etc. to locate relevant code. The Agent also uses compress_session(), ensuring it gathers the right context before attempting any changes.
At step two, the Agent reproduces the issue. It runs all existing tests to ensure a clean baseline, writes a script that triggers the bug (covering all possible edge cases), sets up the environment, and runs the script via shell("python ...") to confirm the failure. Then debug_script() takes over — a custom sub-agent that uses pdb to debug, modify, and generate scripts. Powered by Claude 4 with o4-mini for summarizing the debug info, it’s called at least once — and up to three times — per task. In practice, it was really helpful for digging into the problem source.
Once complete, the Agent plans and applies the fix based on the debugging report. It updates project files directly, without creating patches and diffs. In the earlier run, this step used a separate strategic_planning() tool. With Claude 4 Sonnet, that’s no longer needed — the model’s reasoning is strong enough to handle this job on its own. Finally, the Agent checks its work: re-runs the reproduction script and the project’s existing tests to validate the fix. If all tests pass, it uses compress_session() to offload any debug or temporary files and optimize context usage before ending the run.
Throughout the run, automatic guardrails help keep the Agent on track. These are mid-run messages, inserted into the chat as if from a simulated “user” when the model gets stuck or makes mistakes. A script statically monitors Claude 4’s outputs, and when needed, injects messages to guide the model back on course. For example, it may remind the model to open all visited files after debug_script(), or to follow correct implementation rules after planning. These small actions make a big difference in stability.
The entire run is fully autonomous: no manual inputs, no retries. Each task runs in a single session, with the Agent self-correcting and managing context to stay efficient and produce a single correct solution.
SWE-bench Verified vol.2: What changed in the new run
Several upgrades helped push Refact.ai Agent from 70.4% to 74.4% on SWE-bench Verified:
- Model upgrade to Claude 4 Sonnet: Replaced Claude 3.7 with the more advanced Claude 4 Sonnet.
- Removed
strategic_planning(): Previously, this tool (powered by o3) reasoned overdebug_script()output and modified files This is now fully handled by Claude 4 Sonnet. - New safeguard for file overload: Agent used to open entire folders using
cat, leading to context overflow. We’ve added a limit: if a folder contains more than 5 files, the Agent returns an error and asks for one-by-one access: (“Too many files were requested. Please open files one by one”). - Extra guardrail at the end of the session: “Check the last time that all changes applied to the project directly and all pre-existing tests aren’t broken”.
- Larger context for
search_pattern(). - Minor tweaks to
debug_script()prompt.
All these improvements work together to make Refact.ai Agent more robust and efficient. Moving to Claude 4 Sonnet significantly boosted reasoning ability and allowed us to simplify the agent’s loop while still solving more tasks. Meanwhile, the debug sub-agent and guardrails have been enhanced to ensure greater reliability throughout each run.
Evaluation results:
| Total | Solved | Not solved | Solved (%) | Not solved (%) |
|---|---|---|---|---|
| 500 | 372 | 128 | 74.40% | 25.60% |
From benchmark to your IDE
The new #1 SWE-bench result shows the rapid progress of Refact.ai Agent. Ultimately, our focus isn’t only on benchmark scores - it’s on building an AI agent that truly works for real developers. The lessons learned and improvements made for SWE-bench are already finding their way into the product. That means when you use Refact.ai, you’re benefitting from the engineering approach that achieved this benchmark record.
- Solves tasks autonomously, from start to finish
- Fully understands your codebase, not just open tabs
- Transparent by design — every step is visible and reversible
- Integrates with dev tools (GitHub, Web, MCP, and more) to work across your system
- BYOK-friendly or self-hosted if you want full control.
Refact.ai Agent is an AI Agent for software engineering you can trust — and guide when needed. Autonomous when you want it, collaborative when you step in.
If you’re ready to work with an AI that understands your environment, works across your tools, and earns your trust one task at a time — Refact.ai is ready for you. Join our community, see what real developers are building end-to-end, and start programming with Refact.ai Agent today.