RAG in Refact.ai: Technical Details
Retrieval Augmented Generation (RAG) is a technique to generate more customized and accurate AI suggestions by using the entire coding environment as a source of relevant context for code completions and chat queries. If you are not familiar with RAG and the benefits it brings to developers and software companies, you can start with a Meet RAG in Refact.ai text, which explains the basics.
In this blog post, we go through all the details about how it works and how we implemented RAG in Refact.ai AI coding assistant.
Introduction: Why RAG matters in AI coding
Imagine you have 2 files:
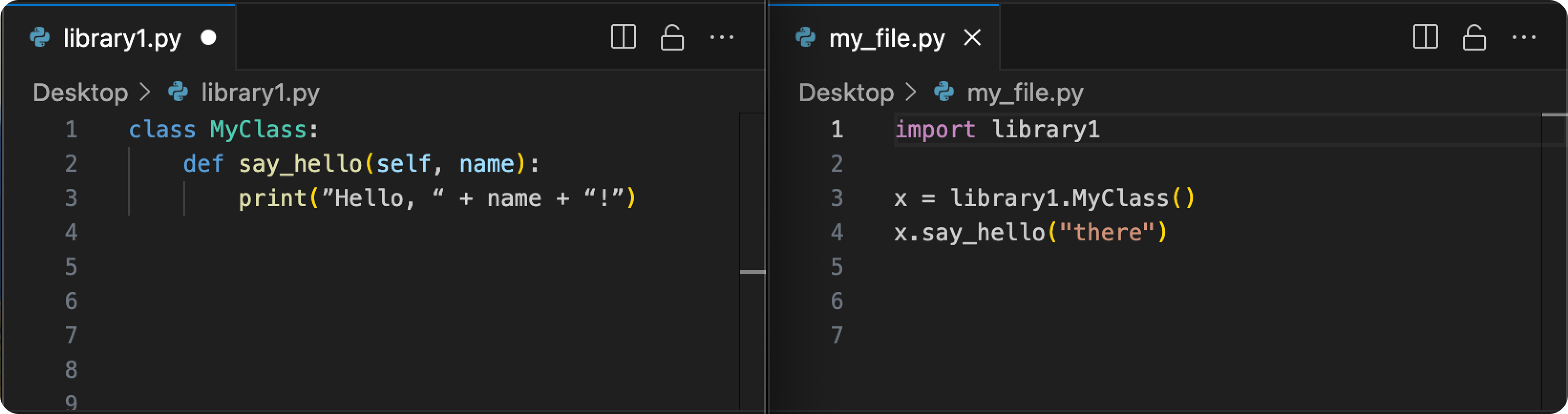
If you just have my_file.py supplied to the model, it doesn’t have any way to know to complete “say_hello” and that it needs a parameter to that function.
This problem of limited scope of AI models gets much worse as your project gets bigger. So, how to fetch it with the necessary information from your codebase, and do it in real time, and accurately?
It takes a specialized RAG pipeline for this work inside your IDE, and that’s the point of our new release.
Refact.ai Technology Stack
We use an intermediate layer between a plugin inside IDE and the AI model called refact-lsp. And yes, it works as an LSP server, too.
Its purpose is to run on your computer, keep track of all the files in your project, index them into an in-memory database, and forward requests for code completion or chat to the AI model, along with the relevant context.
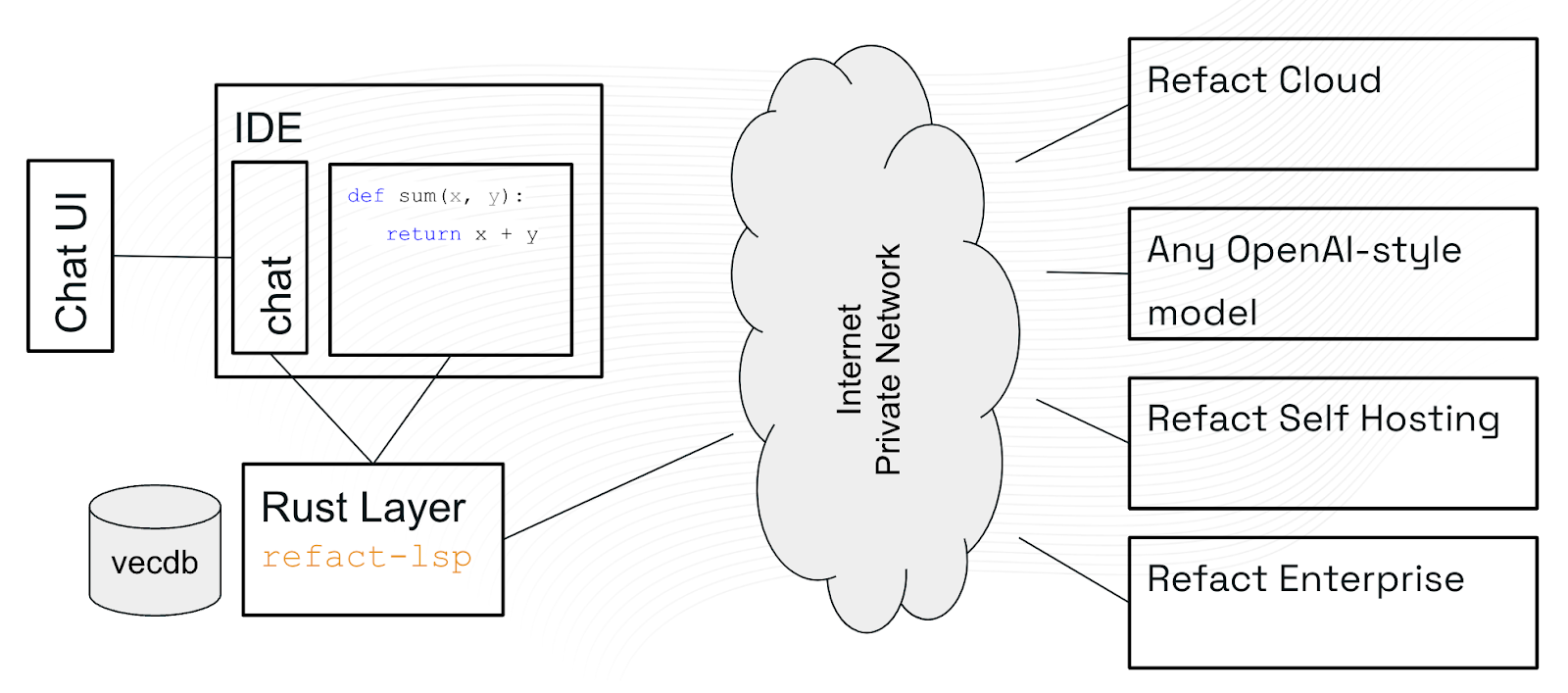
refact-lsp is written in Rust, combining speed of a compiled language and safety guarantees. Rust is great: it has a library for almost any topic you can imagine, including vector databases and a port of tree-sitter — a library to parse source files in many programming languages.
The amazing thing about it: refact-lsp compiles into a single executable file that doesn’t require any other software to be installed on your computer — it’s self-sufficient! It means it will not interfere with whatever you are doing on your computer, and it will not break as you update your environment. In fact you don’t even see it, it gets installed together with the Refact.ai plugin in your favorite IDE.
AST and VecDB
There are two kinds of indexing possible: based on Abstract Syntax Tree (AST) and based on Vector Database (VecDB).
- What is AST? We use
tree-sitterto parse the source files, and then get the positions of function definitions, classes, etc. It is therefore possible to build an index in memory — a mapping from the name of a thing to its position, and make functions like “go to definition” “references” very fast. - What is VecDB? There are AI models that convert a piece of text (typically up to 1024 tokens) into a vector (typically 768 floating point numbers). All the documents get split into pieces and vectorized, vectors stored in a VecDB. These AI models are trained in such a way that if you vectorize the search query, the closest matches (in a sense of l2 metric between the vectors) in the database will be semantically similar or relevant to the query.
The problem with VecDB is that you need to vectorize the query as well, and that might take some time — not good for code completion that needs to be real-time.
It’s not an issue for a chat though: here you can play with both indexes using @-commands. More about it is described a few sections down.
VecDB: Splitting the Source Code Right
To vectorize a piece of text, we first need to make sure it’s a complete construct in a programming language, such as a single function, a single class. This way the semantic matching offered by VecDB will work best.
The easiest way to implement this is to use empty lines as a hint for the boundaries to split:
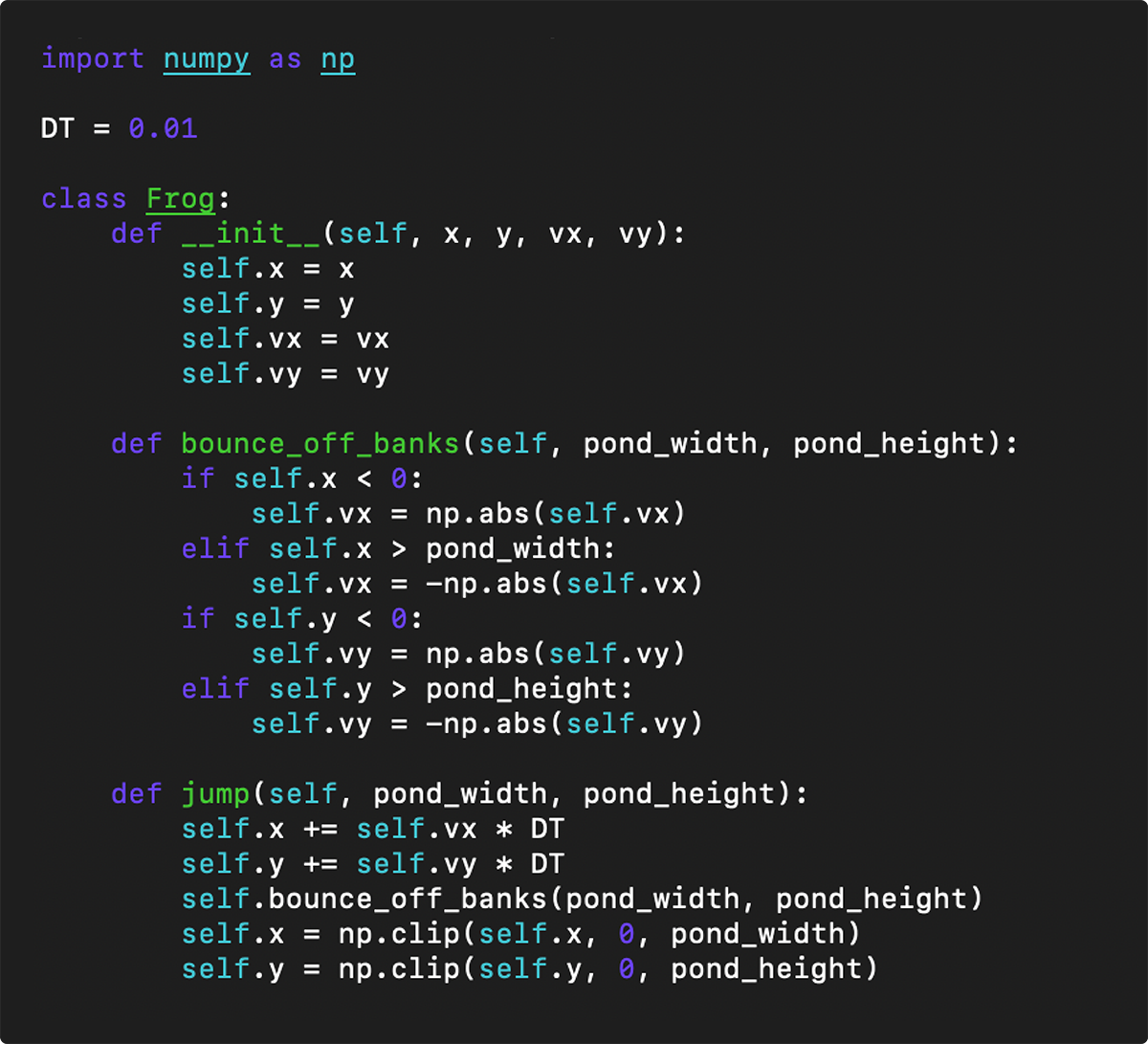
You can see in this example that the functions are separated by an empty line. We in fact use this method for text files without an available tree-sitter module.
But can we do better in splitting as well? Sure, of course we can! We can simplify the class by shortening function bodies:

If this skeletonized version of the class gets vectorized, you can see it’s much easier to match it against a query when you search for things like “classes that have jump in them”, compared to the situation when the splitter just vectorized “jump” function without its class.
AST: Simple Tricks to Make It Better
A library like tree-sitter can transform the source code into individual elements: function definitions, function calls, classes, etc.The most useful case: match types and function calls near the cursor with definitions.
But besides this simple matching, there are some tricks we can do. For the symbols near the cursor, we can first look at their type, and then go to the definitions. And for classes, we can go to their parent class. Those are simple rules that work for all programming languages!
Finally, treating all the identifiers as just strings, we can find similar pieces of code - it should have similar identifiers in them. A similar code can help a model to generate a good answer as well.
Post Processing
Let’s say you’ve found in the AST and VecDB indexes 50 interesting points that might help the model to do its job. Now you have additional issues to solve:
- There might be just too many results to fit into the AI model’s context. There’s a budget measured in tokens to fit memory requirements, or latency requirements (code completion is real time), or model limitation.
- The results themselves might not make much sense without at least a little bit of structure where it appears. For example, for a “function do_the_thing()” it’s important to show it’s inside a class, and which class.
- There can be overlapping or duplicate results.
Those problems can be solved with good post-processing.
This is how our post-processing works:
-
It loads all files mentioned in the search results into memory, and it keeps track of the “usefulness” of each line.
-
Each result from AST or VecDB now just makes an increase in the
usefulnessof the lines it refers to. For example, if “my_function” is found, all the lines that define my_function will increase in usefulness, and the lines that contain the signature of the function (name, parameters and return type) will increase in usefulness more, compared to its body. -
All that is left to do is to sort all the lines by usefulness, then take the most useful until the token budget is reached, and output the result:
You see there, post-processing can fit into any token budget, keeping the most useful lines, and rejecting less useful ones, replacing them with ellipsis.
One interesting effect is skeletonization of the code. As the budget decreases, less and less lines can make it into the context, our post-processing prefers to keep some of the code structure (which class the function belongs to) over the body of that function.
Oh Look, It’s Similar to grep-ast!
Yes you are right, it is! In fact we took inspiration from grep-ast, a small utility that uses tree-sitter to look for a string in a directory, and it also prefers to keep the structure of code so you can see where logically in the code your results are.
It doesn’t have a notion of token budget though, and it’s written in python so it’s not very fast, and it doesn’t have any indexes to search faster.
RAG in Refact.ai Chat with @-commands
In Refact.ai, we’ve made RAG support for chat LLMs too. It can be used with commands to add some important context.
@workspace- Uses VecDB to look for any query. You can give it a query on the same line like this: “@workspace Frog definition”, or it will take any lines below it as a query, so you can search for multi-line things like code pieces.@definition- Looks up for the definition of a symbol. For example, you can ask: “@definition MyClass”@references- Same, but it returns references. Example: “@references MyClass”.@file- Attaches a file. You can use file_name:LINE1-LINE2 notation for large files to be more specific, for example “@file large_file.ext:42” or “@file large_file.ext:42-56”.@symbols-at- Looks up any symbols near a given line in a file, and adds the results to the chat context. Uses the same procedure as code completion does. For it to work, you need to specify file and line number: “@symbols-at some_file.ext:42”.
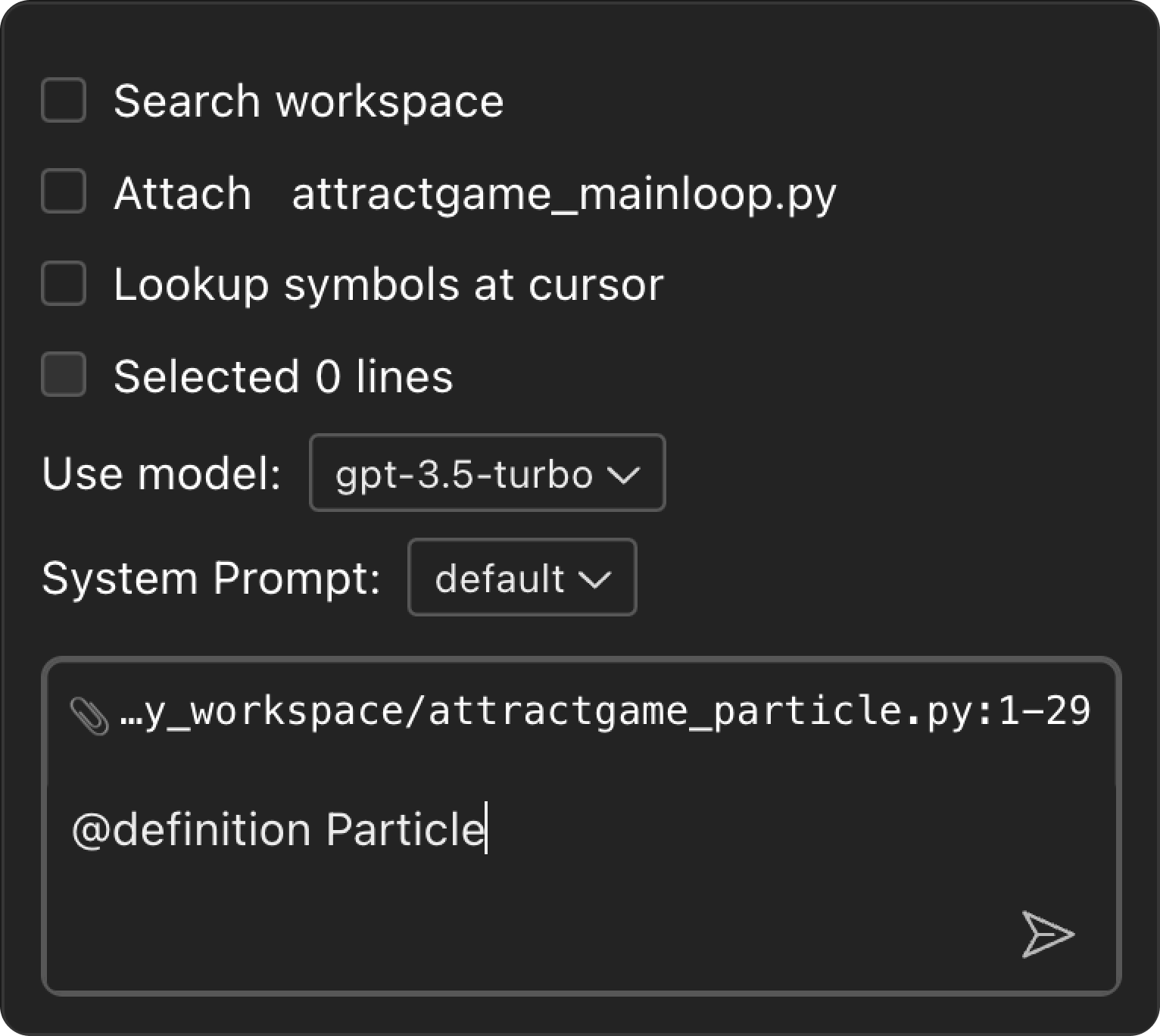
When you start a new chat, there are options available:
- “Search workspace” is equivalent to typing
@workspacein the input field: it will use your question as a search query. - ”Attach current_file.ext” is equivalent to “
@file current_file.ext:CURSOR_LINE” command that attaches the file, and uses the current cursor position (CURSOR_LINE) to deal with potentially large files. - ”Lookup symbols” extracts any symbols around the cursor and searches for them in the AST index. It’s equivalent to “
@symbols-at current_file.ext:CURSOR_LINE”. - ”Selected N lines” adds the current selection as a snippet for model to analyze or modify, it’s equivalent to writing a piece of code in backquotes
```my code```
Interesting Things You Can Try with RAG
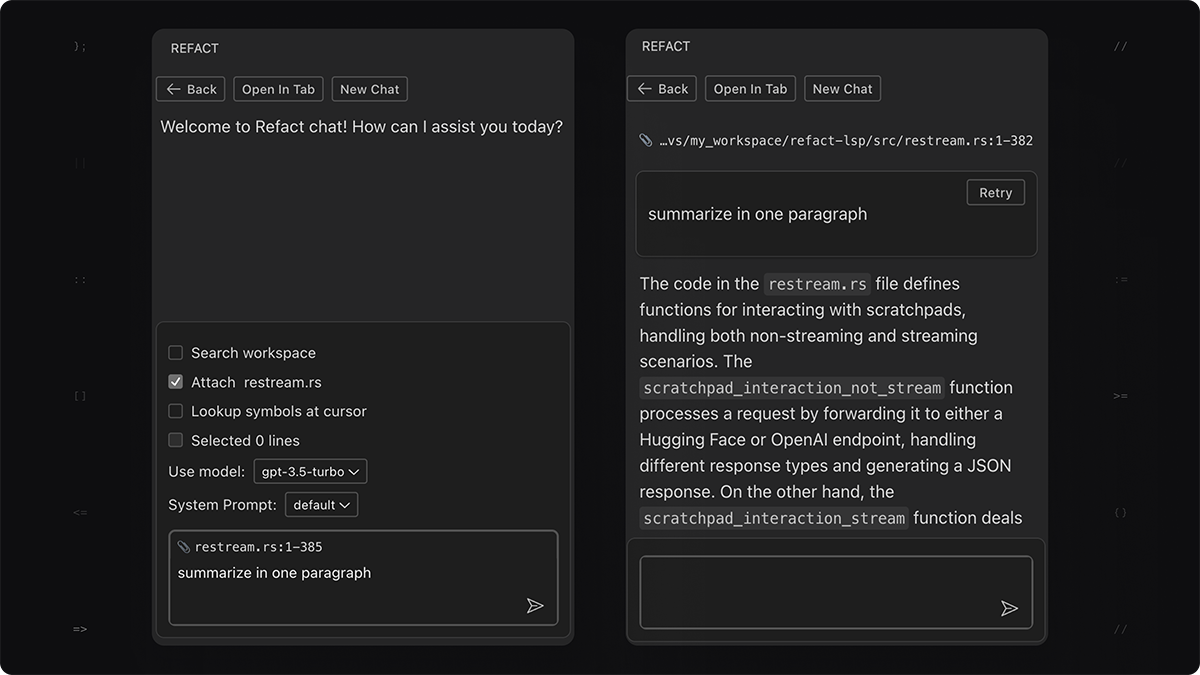
Summarize a File
Take a large file, open chat (Option+C) or toolbox (F1), and type “summarize in 1 paragraph”. The post-processing described above makes the file fit the chat context you have available. Check out how the file looks in the tooltip for the 📎 Attached file. The bigger the original file, the more skeletonized version you’ll see.
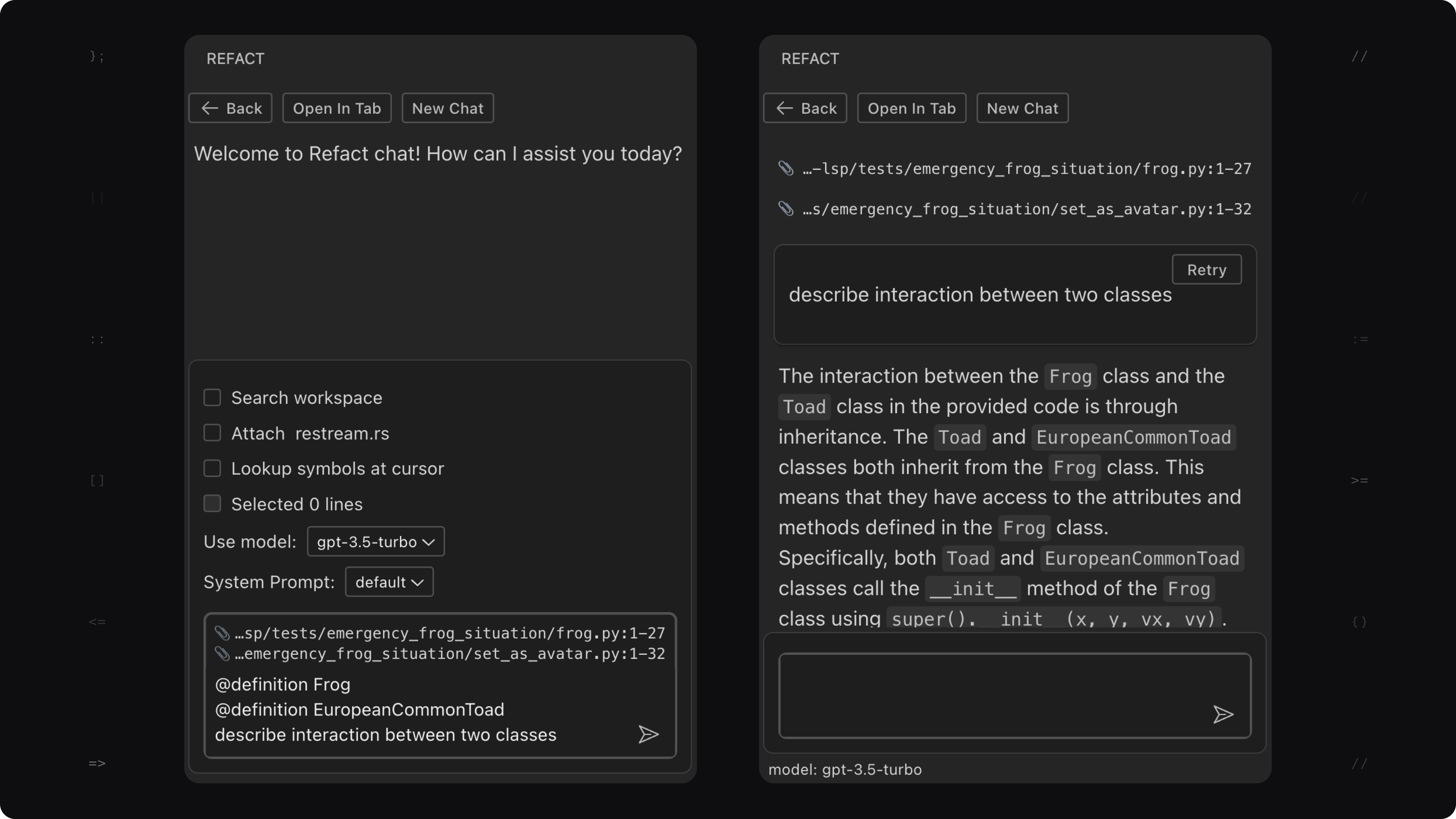
Summarize Interaction
Unfamiliar code is a big problem for humans: it might take hours to understand the interaction of several classes. Here’s another way to do it: use @definition or @file to put the classes of interest to the context, and ask chat how they interact.
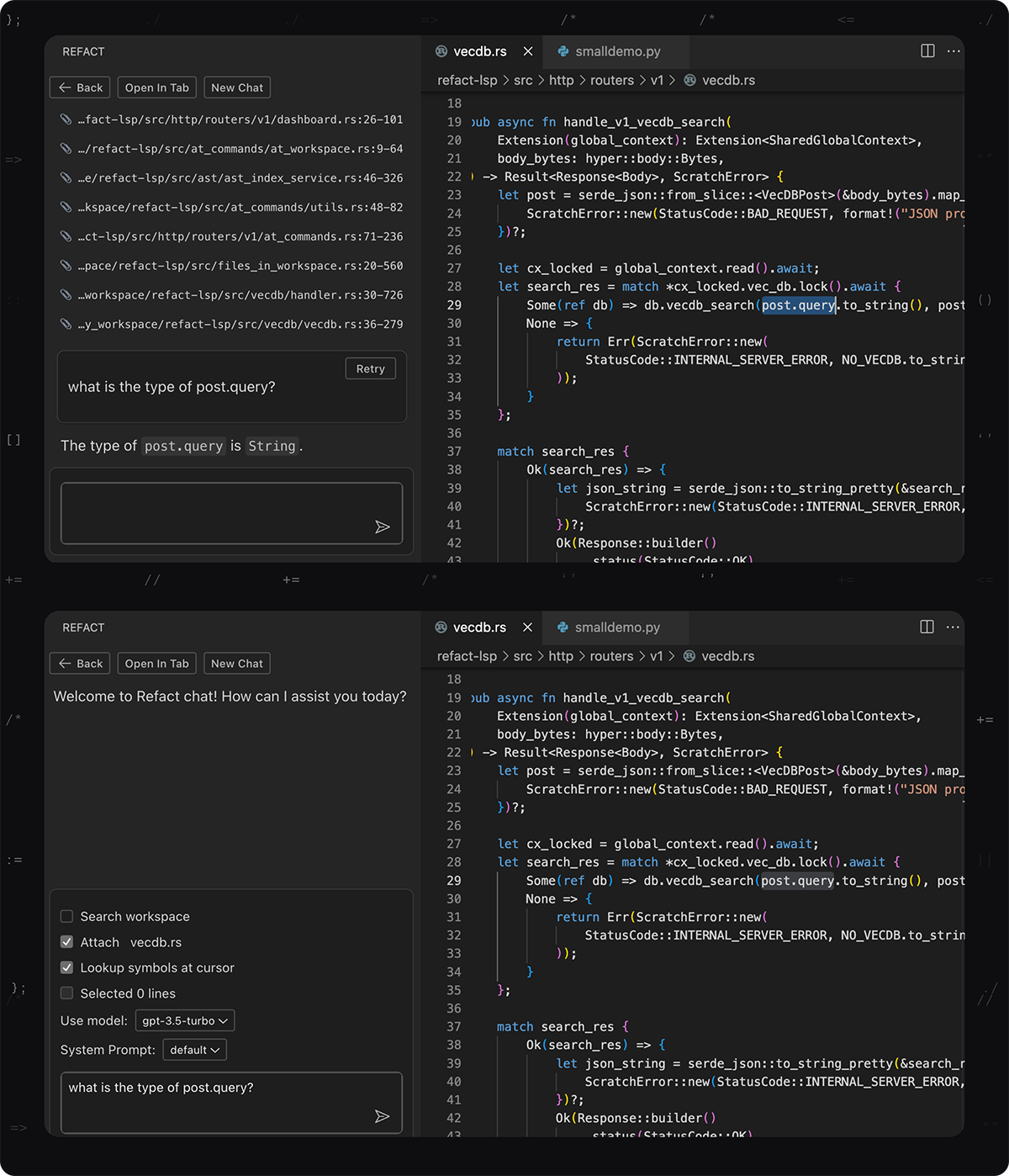
Code Near Cursor with Context
You can add context to chat using the same procedure as code completion: use “Lookup symbols near cursor” or @symbols-at command.
So How Good Is It?
We tested code completion models with and without RAG, and here are the results.
We’ve made a small test that is easy to understand and interpret, it works like this: take 100 random repositories from github for each programming language, delete a random string in a random function, and run single-line code completion to restore it exactly.
It is not perfect, because sometimes it’s hard to reproduce comments exactly (if there’s any on the deleted line), and there are many easy cases (like a closing bracket) that will not benefit from RAG at all. But still it’s a good test because it’s simple! Here is the dataset.
The results of the test (running StarCoder2/3b):
| Language | Without RAG activated | With RAG |
|---|---|---|
| Python | 46% | 51% |
| Java | 49% | 60% |
| C++ | 48% | 53% |
| Typescript | 43% | 49% |
Takeaways:
- RAG always helps!
- It helps Java more than Python, because many projects in Python don’t use type hints.
Limitations
For Python code like this:
def f(x: MyClass):
x.do_somethingThe MyClass type is optional, it’s called type hints. The AST index that Refact uses for real-time completion can’t pick up the type definition if it’s not there.
For database schema definition like this:
mydb.execute("""
CREATE TABLE customers (
id INTEGER PRIMARY KEY,
name TEXT,
email TEXT,
);
""")There is no way for AST to index the SQL table customers and include it into context whenever you write an operation on that table.
Discover RAG with a Free 2-Month Trial of Refact.ai Pro
RAG is now available for Pro and Enterprise users at Refact.ai without any extra fees.
Exiting news: To celebrate the launch of RAG, we’re offering you an opportunity to try it with no limits for your coding projects:
🎉 Start your free 2-month trial of the Refact.ai Pro plan, RAG included!
Steps to Activate Your Pro Trial:
- Visit our Pricing page and upgrade your account to the Pro plan.
- Apply the
REFACTRAGpromo code to activate your Pro plan. - Receive an email with instructions on how to enable RAG in your plugin!
If you like what we’re doing, please leave us a ⭐⭐⭐⭐⭐ on marketplaces - this will support our work.
Join our Discord to talk about RAG or give us feedback. We’ve set up a special #rag channel for your questions, and our team is there to help.
Give RAG a try to empower your programming with advanced coding suggestions. Have fun!