Programming with AI: Our Dream
TL;DR: It’s the early days of AI autonomously working as a software engineer. A human is still required to steer these capable systems. We at Refact look at potential UI, speed, cost, and tradeoffs.
Not Solving SWE-Bench
Let’s quickly get the SWE benchmark out of the way. Some people still look at this benchmark as a primary measure of capability of a coding agent - it isn’t.
SWE-bench consists of real issues in open-source repositories. But there are some problems:
- All repositories in SWE-lite are in Python
- There are just 12 of them (django, sympy, …)
- All models are already familiar with these open source repositories
- Correct output is always 1 file changed
But the problems for SWE-Bench don’t end there. Sure, there’s some value in just using the description given by a submitter on github, but it’s not realistic for a real human-machine interface. Humans can learn, and they will adapt to the AI they use. They will know what kind of tasks an agent can solve, what it cannot, and only give the tasks that are likely to succeed.
Then the question becomes: what kind of agent is best for a human to achieve high speed and comfort in programming?
And by the way, robots can learn, too, collecting information about the project over time, and that capability is not measured by SWE-Bench - all the projects used are open source and already memorized by all the models. Not true for any new code or proprietary code that requires adaptation.
(Hey, if you are a student and you are looking for a good task to work on, make a better benchmark! It does not require a massive GPU farm, and will earn you a lot of citations for your paper. But find other people to cooperate on this, don’t do it on your own.)
Interactive vs Long Thinking AI Agents
Here’s one interesting trade-off: the current AI agents are slow.
The reason they are painfully slow is that they need to find a good cross-section of the repository at hand, generate and verify one or several solutions. Each of those operations requires at least one call to a state-of-the-art model (usually behind an API) with a lot of tokens. For this reason, agents are also expensive to run.
But let’s talk about speed. Is it possible to create a fast intelligent agent that can be used interactively? Does it mean it’s necessarily stupid, compared to a slow-thinking counterpart?
Is it possible to build a lovable product that embraces the slowness instead? This will require a completely different approach for a human: start several tasks, go have some tea, and when you come back some results will be ready. What are the requirements for this kind of AI agent to be usable?
For Refact.ai, what should be the priority? Let’s see if we can spot some trends.
Coding assistants started as an interactive feature: code completion. There were no slow-thinking products at all, and there are still none in coding assistants that are ready for prime time.
Over time, models become cheaper, faster and smarter. The reason why we are talking about a long-thinking agent for developers at all - is the “smarter” part. There’s no use in running a stupid model for a long time, it will just produce a lot of stupid.
But fixing the “smarter” part at a constant, as models become cheaper and faster, what will happen to a slow-thinking agent, will it become fast-thinking automatically, and therefore interactive? Or the slow AI agent will not ever go away: if a slow agent of today becomes fast tomorrow, we can always add more work and it will become slow again?
Refact.ai Approach
Well, we don’t know what people will like more.
On the technical side, the approach that should stand the test of time is to make building blocks that are useful in either scenario, and the difference between interactive and slow non-interactive regime is just the top-level system prompt.
An argument might go both ways: interactive agents are great because they are steerable along the way, and we want to keep a human in control. Non-interactive agents are also great: most tasks are not that complicated, just shut up and do the work.
We’ve figured the best way to decide these things is to speak to actual developers, and let them try an early version of Refact.ai AI agent. There’s a group of about ten enthusiastic people that we selected, we’ll try to know their problems and shape our future product together with these people. You can fill this form if you want to participate in this too, but the probability is low that we’ll add a lot of people, however - because of the cognitive load.
Refact.ai Future User Interface
Let’s talk about a less-than-realtime UI. What should it look like, if you want to launch a task and forget about it for 5-15 minutes?
Well, if they are so slow, you probably want to run several of them at the same time. You might also want to specify exactly what you want. If it takes considerable time to write a longer description, by the time the first one finishes or fails, your next task description might already be ready.
From that, several sessions need to work at the same time in the UI. Unfinished task descriptions or follow ups should reliably stay in place when you switch between sessions.
Furthermore, Refact.ai is an open source AI tool, and have nothing to hide. We’ll present all the internal model calls in the UI as well. How exactly a diff is generated by the autonomous agent? You will be able to see that.
One With the Machine
There are 4 main factors that make an AI agent useful:
- Intelligence of the underlying models
- Quality of the tools available to the model
- Learning curve for a human
- Speed and comfort for a human once adapted
We at Refact work mostly on tools: we have functions for Abstract Syntax Tree access, VecDB search, AI expert calls, and more. In this blog, the question is - what makes it an enjoyable experience?
Observable. It must be clear what’s going on with a task. That includes any failures: models sometimes go in circles, or go off the rails. This should all be transparent to the user, easy to understand. Based on that information, the user can correct their future tasks, or report the failure to improve the product.
Open and customizable. Other companies might hide the internals from you, but Refact is open source. If you see how an internal expert calls work in UI, you can understand the underlying technology, or even customize it.
Diffs. Software engineers use version control systems (like Git or Mercurial) every day. If there are a lot of changes produced by a single agent invocation, it needs to closely match the already familiar concepts: simple diffs for the interactive use case, ready-to-pull commits or small branches for the slow-thinking use case.
Memory. You should be able to tell how to solve a certain problem, and the model needs to memorize that, so it wouldn’t get stuck in a similar situation later. Or you can just tell your preferences directly.
Adaptation to the project. Over time, the AI agent should build a project-specific knowledge base, especially successful and unsuccessful attempts at doing things to improve the success rate in the future.
Enough with the Dreams, What’s Reality?
We want to build Refact.ai AI agent as a product people will love.
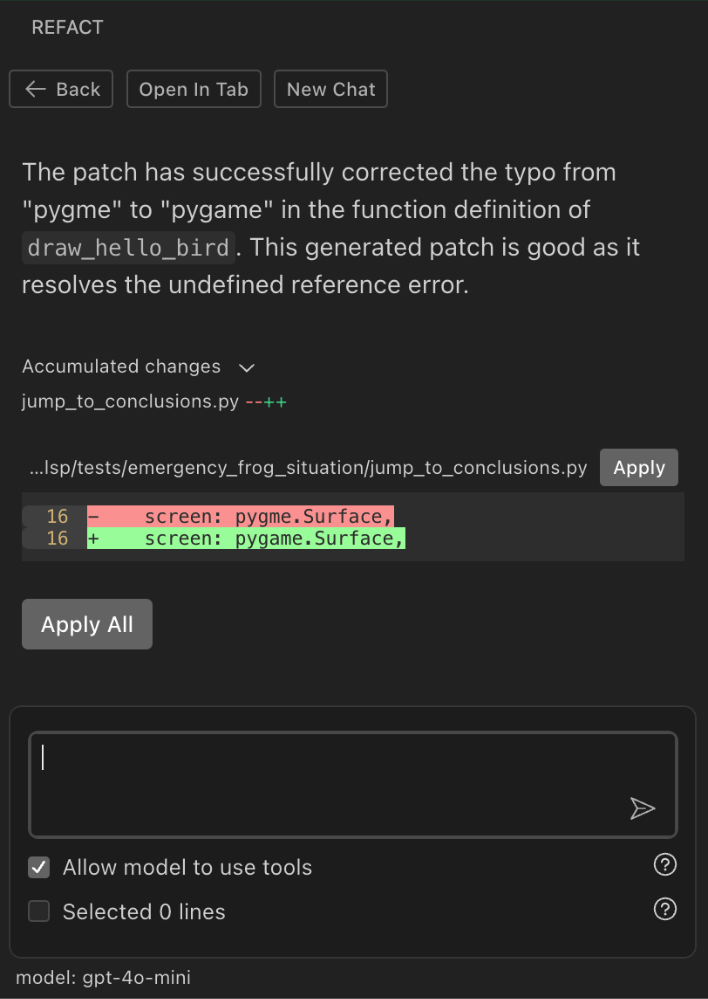
We have just posted a pre-release version in the VSCode Marketplace. It’s experimental, not yet recommended for anyone other than enthusiasts. But it won’t be experimental for long; on August 19, we plan a stable release for everybody!
You will be able to turn autonomous agent features off for each chat: in that case, Refact.ai will be an AI coding assistant with RAG tools.
When the agent feature is turned on, the chat will use a different system prompt and a different set of tools, and will find and patch relevant files on its own. We should be able to go through a couple of cycles of real-world feedback by then, to make the UI experience well polished.
The next version in September will offer Docker container isolation to perform automatic verification of the changes and memory. This way, Refact.ai’s autonomous agent will be available for Enterprise users.
We’d love your feedback:
- Join our Discord to discuss new functions or share feedback
- Check Refact.ai GitHub for our source code — Refact.ai is an open-source AI coding assistant and welcomes your contributions!
- Please rate us on VS Code and JetBrains
- And stay (fine-)tuned for further updates!