Open-source Fine-Tuning on Codebase with Refact
Code completion has become increasingly popular, thanks to tools like GitHub Copilot and open-source Large Language Models (LLMs). However, both Copilot and open models often fall short when it comes to working effectively on your specific codebase. This is because these models have never been exposed to your unique code patterns and conventions.
In order to improve the quality of suggestions and tailor them to your codebase there’s a technique called fine-tuning. By fine-tuning a pre-trained model on your codebase, you can improve its ability to understand and generate code that aligns with your requirements.
In this blog post, we will delve into the concept of fine-tuning, and its technical details, and show how you can start self-hosting your fine-tuned model in Refact.
Example
In this video, the same simple function is generated by: Copilot, base Refact 3b model, fine-tuned Refact 3b model.
All three can look down the code, find what variables are necessary, and help you with typing, but only the finetuned version knows how to work with DatasetOpts.
How Exactly Fine-tune Works?
Large language models work by predicting the next token. This simple objective allows LLMs to learn syntax, code patterns, and even high-level concepts.
The code you write is probably different from all the other projects on the internet. It might be similar - that’s why code LLMs are already useful - but you probably have your own established way to do things.
One simple example is coding style. Predicting the next token in a certain way defines how a model writes code, including variable names, spaces, etc.
Fine-tuning has the same objective as pre-training: predict the next token. By adjusting the parameters in a clever way (it needs only one GPU to train!), the model starts to predict the next token according to your coding style, as well as patterns, your typical API usage, etc.
That’s why you’ll see more useful suggestions if you are using a fine-tuned model.
What Data Can I Use for Fine-tuning the Model?
In Refact UI, you will need to upload source code, in archive form (.zip, .tar.gz, .bz2) or give it a link to a git repository (private git repositories work too, you need to generate a ssh key though). You can upload an individual file, too. Refact then will slice your source code into pieces that a model can actually train on.
It’s a good idea to give the model the current code of your projects. However, it’s NOT a good idea to feed 3rd party libraries that you use, as the model may learn to generate code similar to the internals of those libraries.
Test Loss
In order to measure how well the model is adapted to your code, you can take one or two of your files and make it a test set. To be meaningful as a measurement, these files should be using your coding style, your libraries and APIs.
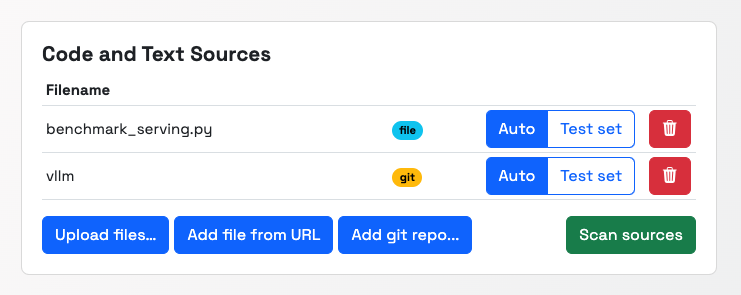 Picture: shows
Picture: shows vllm github repository as a training set, and a single file benchmark_serving.py as a fixed test setIf test files are also present in the train set, they will be automatically subtracted from it.
If you don’t specify any test set, it will pick several random files for you.
Technical Details
It’s possible to fine-tune all parameters (called “full fine-tune”), but recently PEFT methods became popular. PEFT stands for Parameter-Efficient Fine-Tuning. There are several methods available, the most popular so far is LoRA (2106.09685) that can train less than 1% of the original weights.
LoRA has one important parameter — tensor size, called lora_r. It defines how much information LoRA can add to the network. If your codebase is small, the fine-tuning process will see the same data over and over again, many times in a loop. We found that for a smaller codebase small LoRA tensors work best because it won’t overfit as much — the tensors just don’t have the capacity to fit the limited training set exactly.
As the codebase gets bigger, tensors should become bigger as well. We also unfreeze token embeddings at a certain codebase size.
To pick all the parameters automatically, we have developed a heuristic that calculates a score based on the source files it sees. This score is then used to determine the appropriate LoRA size, number of finetuning steps, and other parameters. We have tested this heuristic on several beta test clients, small codebases of several files, and large codebases like the Linux kernel (consisting of about 50,000 useful source files).
If the heuristic doesn’t work for you for whatever reason, you can set all the parameters yourself.
How to Test If It Worked?
After the fine-tuning process finishes (which should take several hours), you can dynamically turn it on and off and observe the difference it makes for code suggestions. You can do this using this switch:
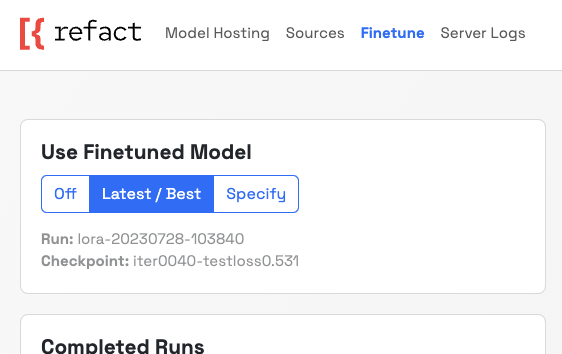
There’s a catch: both VS Code and JB plugins cache the responses. To force the model to produce a new suggestion (rather than immediately responding with a cached one), you can change the text a few lines above, for example, a comment.
Alternatively, you can use the Manual Suggestion Trigger (a key combination), which always produces a new suggestion.
Self Hosting
You can use your own GPU to host and fine-tune LLMs with Refact self-hosting server.
FAQ
Q: Maybe models can guess code better if they have more context, especially from other files?
A: For the best results, you need both. Fine-tuning gives you the coding style, and if the model can see relevant snippets of code from other files, it will work better for calling functions and using types defined outside of the current file. We are currently working on that, too. Join our discord server and be the first to know when we release it!
Q: I only want to imitate the coding style of certain experts on my team. Is this possible?
A: Certainly! It is indeed possible to imitate the coding style of specific experts on your team. You can achieve this by selectively uploading the files that represent the desired coding style and excluding any old or low-quality code. By doing so, the model will generate code that aligns with the chosen coding style. This approach can be valuable in transferring expert knowledge within your company, as the coding assistant can consistently suggest good coding practices.
